
Implementation Examples#
LSGM: Score-based Generative Modeling in Latent Space#
LSGM: Score-based Generative Modeling in Latent Space trains a score-based generative model (a.k.a. a denoising diffusion model) in the latent space of a variational autoencoder. In the latent score-based generative model (LSGM), data is mapped to latent space via an encoder \(q(z_0|x)\) and a diffusion process is applied in the latent space \((z_0 → z_1)\). Synthesis starts from the base distribution \(p(z_1)\) and generates samples in latent space via denoising \((z_0 ← z_1)\). Then, the samples are mapped from latent to data space using a decoder \(p(x|z_0)\). The model is trained end-to-end. It currently achieves state-of-the-art generative performance on several image datasets.

Hierarchical Text-Conditional Image Generation with CLIP Latents#
Hierarchical Text-Conditional Image Generation with CLIP Latents
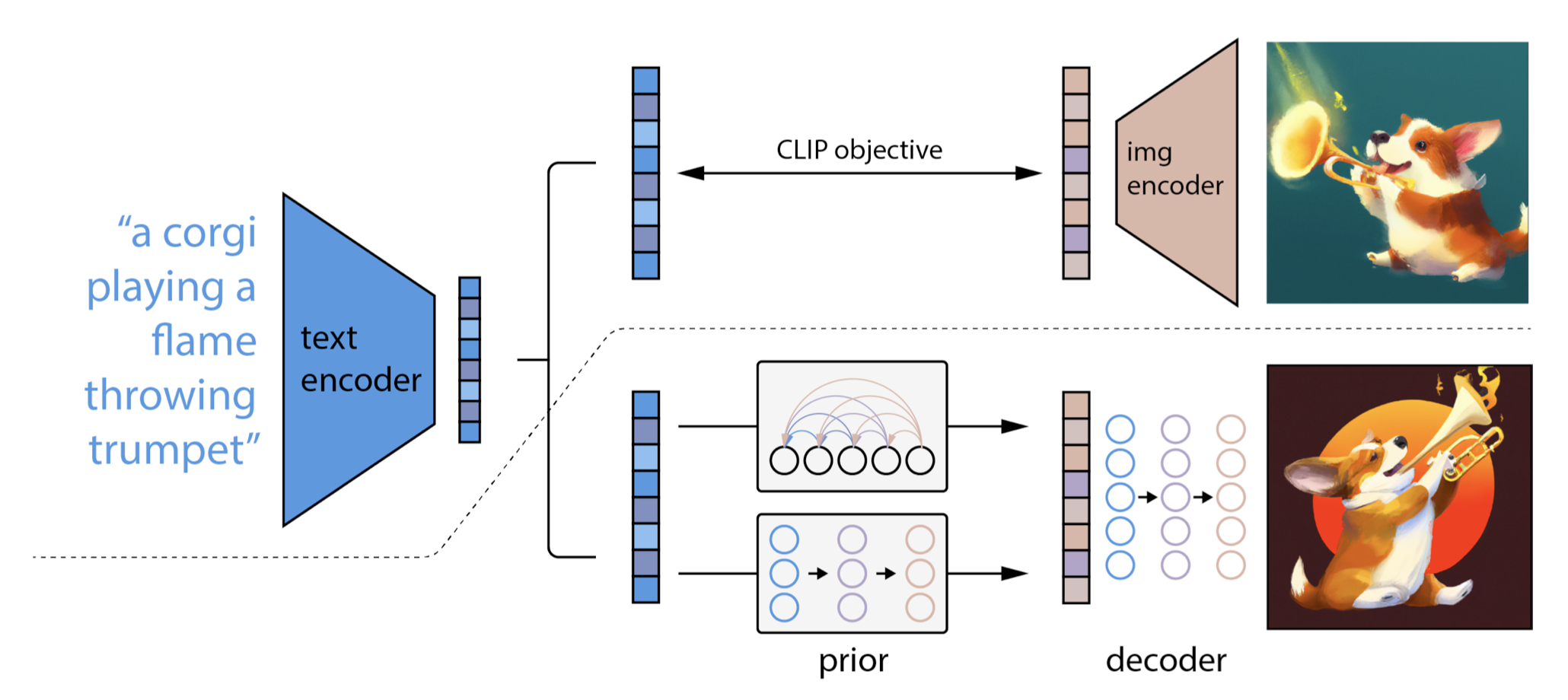
The two-stage diffusion model unCLIP heavily utilizes the CLIP text encoder to produce text-guided images at high quality. Given a pretrained CLIP model and paired training data for the diffusion model, \((x,y)\), where \(x\) is an image and \(y\) is the corresponding caption, we can compute the CLIP text and image embedding, \(c^t(y)\) and , \(c^i(x)\) respectively. The unCLIP learns two models in parallel:
A prior model \(p(c^{i}|y)\): outputs CLIP image embeddings \(c^i\) given the text \(y\)
A decoder \(p(x|c^{i},[y])\): generates the image \(x\) given CLIP image embedding \(c^i\) and optionally the original text \(y\).
LION (NeurIPS 2022):#
LION: Latent Point Diffusion Models for 3D Shape Generation
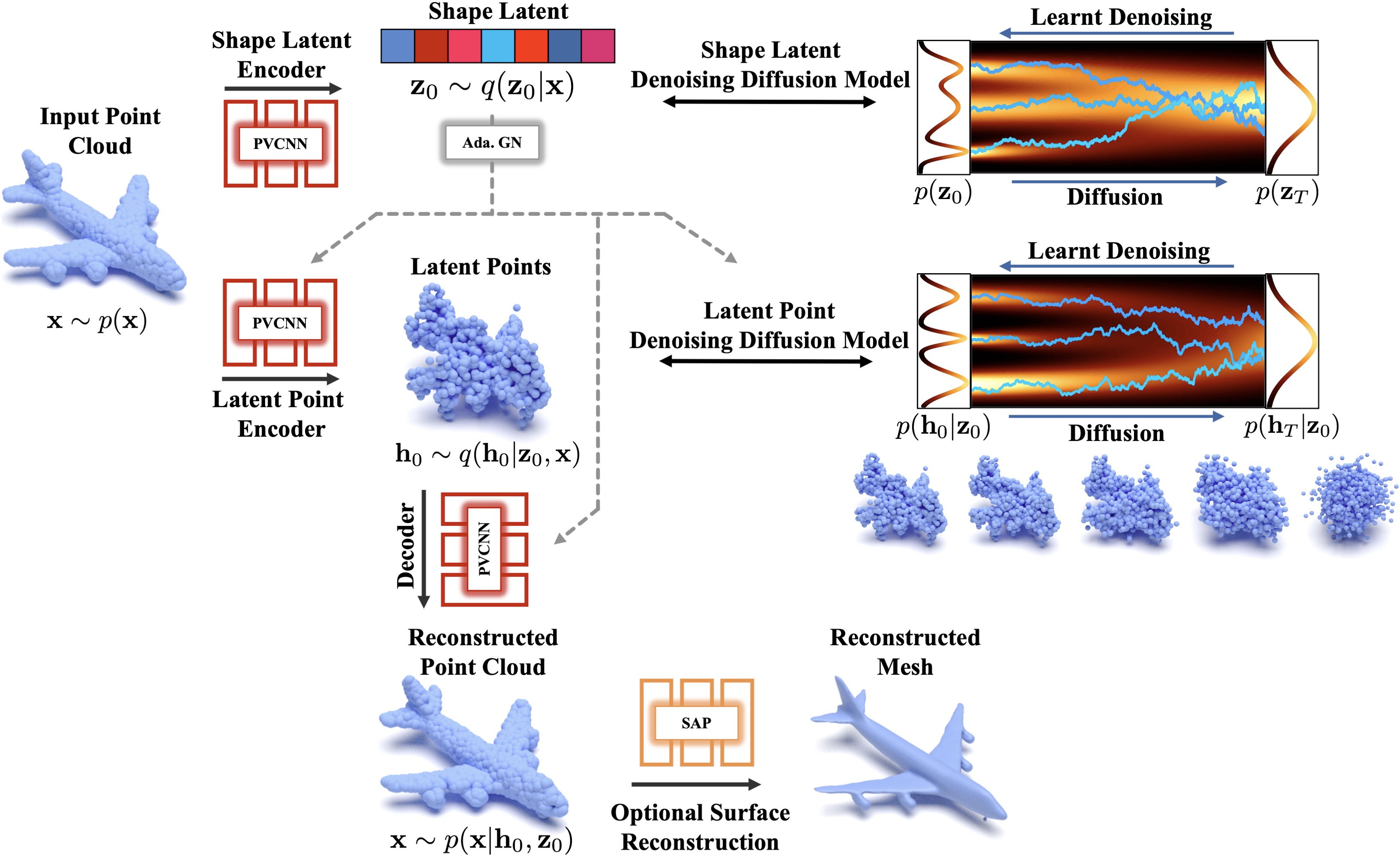
They introduce the hierarchical Latent Point Diffusion Model (LION) for 3D shape generation. LION is set up as a variational autoencoder (VAE) with a hierarchical latent space that combines a global shape latent representation with a point-structured latent space. For generation, they train two hierarchical DDMs in these latent spaces. The hierarchical VAE approach boosts performance compared to DDMs that operate on point clouds directly, while the point-structured latents are still ideally suited for DDM-based modeling.
MeshDiffusion: Score-based Generative 3D Mesh Modeling#
MeshDiffusion: Score-based Generative 3D Mesh Modeling MeshDiffusion Repository

The paper presents a novel approach to generating realistic 3D shapes, a task that has applications in automatic scene generation and physical simulation. The authors argue that meshes are a more practical representation for 3D shapes than alternatives like voxels and point clouds, as they allow for easy manipulation of shapes and can fully leverage modern graphics pipelines.
Previous methods for generating meshes have relied on sub-optimal post-processing and often produce overly-smooth or noisy surfaces without fine-grained geometric details. To overcome these limitations, the authors propose a new method that takes advantage of the graph structure of meshes and uses a simple yet effective generative modeling method to generate 3D meshes.
The method involves representing meshes with deformable tetrahedral grids and training a diffusion model on this direct parameterization. The authors demonstrate the effectiveness of their model on multiple generative tasks.
Zero-1-to-3: Zero-shot One Image to 3D Object#
Zero-1-to-3: Zero-shot One Image to 3D Object
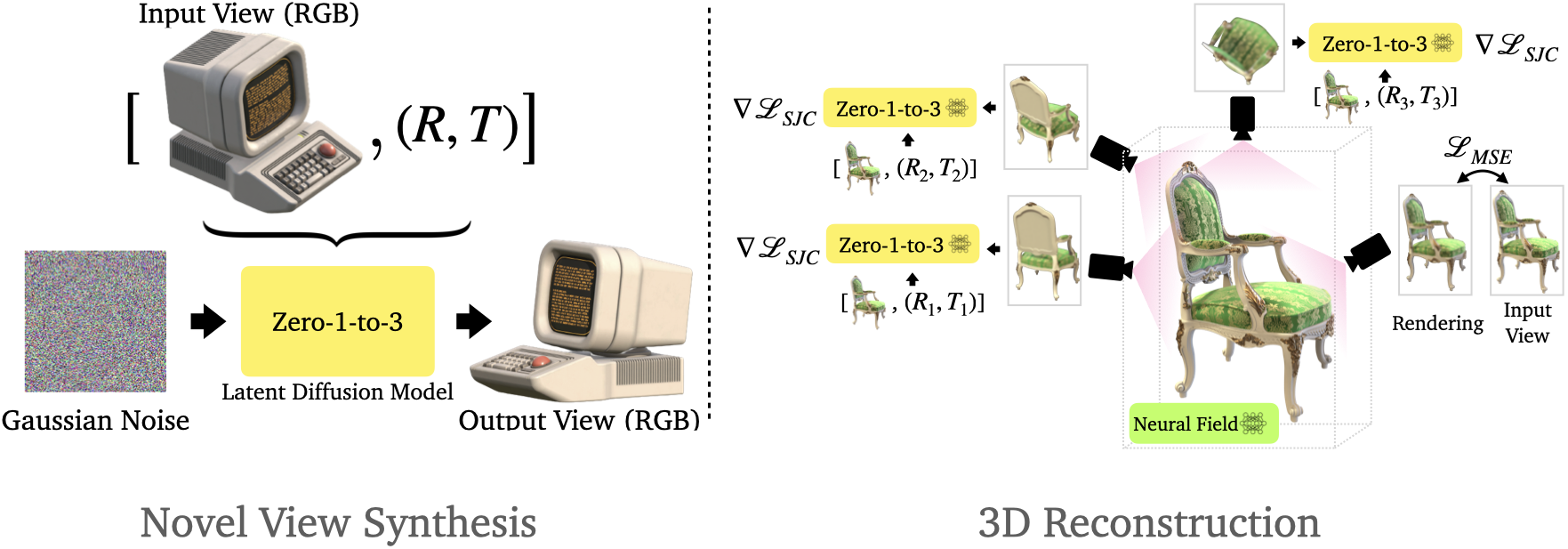
The paper introduces Zero-1-to-3, a framework for changing the camera viewpoint of an object given just a single RGB image. To perform novel view synthesis in this under-constrained setting, they capitalize on the geometric priors that large-scale diffusion models learn about natural images. their conditional diffusion model uses a synthetic dataset to learn controls of the relative camera viewpoint, which allow new images to be generated of the same object under a specified camera transformation. Even though it is trained on a synthetic dataset, our model retains a strong zero-shot generalization ability to out-of-distribution datasets as well as in-the-wild images, including impressionist paintings. Their viewpoint-conditioned diffusion approach can further be used for the task of 3D reconstruction from a single image.
Repository of Implementations for different Approaches of 3D Generative Models#
threestudio: is a unified framework for 3D content creation from text prompts, single images, and few-shot images, by lifting 2D text-to-image generation models.

